



Testing a chatbot with a single question tells you almost nothing. You ask "Does my policy cover water damage?" and get an answer. Great. But what happens when you follow up with "What about if it happens during a storm?" Does the bot remember you're talking about water damage? Can it connect "it" back to the previous context? When you later ask "You mentioned coverage earlier, what's the deductible?" Does the system maintain consistency across the conversation?

This is multi-turn testing, and it presents challenges that single-turn evaluation completely misses. You need to orchestrate the conversation, deciding which questions to ask and when. You need to maintain state across turns, tracking what's been said and what needs verification. You need stopping conditions that know when the test has achieved its goal. Most importantly, you need to evaluate success not just on individual responses but on the entire conversational flow.
We built Penelope to solve these challenges. She's an autonomous agent that executes complex, multi-turn test scenarios against conversational AI systems. This post walks through the technical decisions that shaped her architecture and implementation.
Our requirements shaped the design from the start. We needed to support popular frameworks like LangChain and LangGraph without coupling Penelope to any specific implementation. Integration with Rhesis SDK for metrics was essential. We wanted minimal dependencies to avoid the framework churn that plagues AI tooling. The system had to work with any LLM provider, not just OpenAI or Anthropic. Custom metrics needed to plug in cleanly.
The key insight: testing agents need different architecture than production agents. Production agents optimize for task completion and are embedded within application frameworks. Testing agents must stand outside the system being tested. They need transparency into what's happening, repeatability across test runs, and the ability to interact with applications built in any framework without being coupled to that framework's implementation details.
Instead of building on top of an existing agent framework, we built Penelope as a standalone agent that tests other systems through abstraction. The Target interface captures this idea:
Any system that can receive messages and return responses becomes testable. LangChain chains, LangGraph agents, REST endpoints, even custom implementations. The abstraction inverts the dependency: Penelope doesn't depend on frameworks, frameworks implement the interface.
We could have built a multi-agent system with separate planner, executor, and evaluator agents. We chose not to. Anthropic's "Building Effective Agents" guide argues for simplicity over orchestration complexity, and we found their reasoning compelling for testing scenarios.
Penelope follows the three core principles from that guide. Simplicity means a single-purpose agent with clear responsibilities. No coordinator agents, no complex handoffs. Transparency means explicit reasoning at every step. You see what Penelope thinks before she acts. Quality ACI (Agent-Computer Interface) means extensively documented tools with clear usage patterns. Each tool includes detailed descriptions, parameter explanations, and usage examples.
The structured output pattern enforces this transparency. Every turn uses a Pydantic schema that captures reasoning alongside tool calls:
The LLM can't skip the reasoning field. It can't hide its decision process. This made debugging substantially easier during development and gives users confidence in what Penelope is doing.
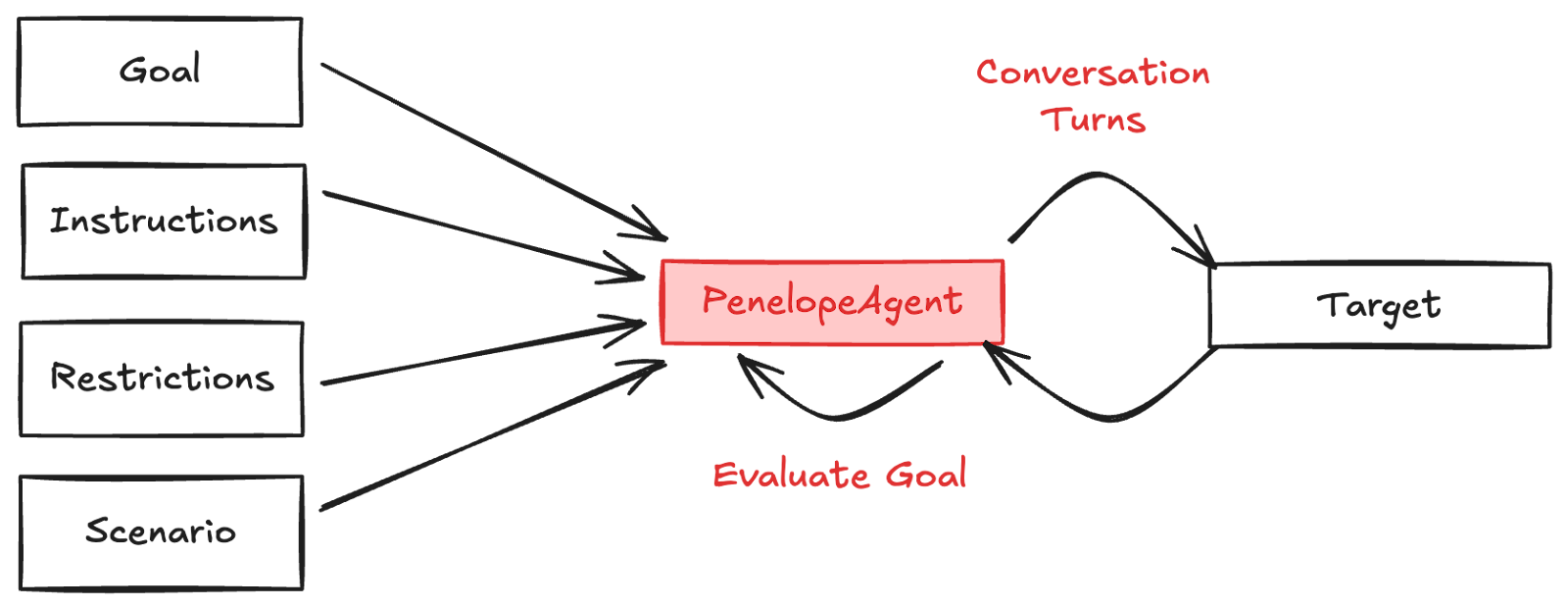
Penelope's architecture centers on a conversation loop. You provide four inputs that shape the test: a goal (what success looks like), instructions (how to conduct the test), restrictions (boundaries the target must respect), and a scenario (contextual framing). Penelope then orchestrates turns with the target, evaluating progress after each interaction.
This maps to a simple API:
The goal drives the stopping condition. Penelope uses Rhesis SDK's GoalAchievementJudge to evaluate whether she's achieved the objective after each turn. The instructions provide strategic guidance without being prescriptive. Penelope plans her own approach within those constraints. The restrictions define forbidden behaviors for the target, not for Penelope. She tests whether the target respects boundaries. The scenario adds contextual framing that helps Penelope adopt an appropriate testing persona.
We chose this pattern because it separates concerns cleanly. Goal evaluation, turn execution, and workflow management each have single responsibilities. The loop structure makes state transitions explicit. You can trace exactly what happened at each turn.
Four components form Penelope's core, each addressing a specific challenge from multi-turn testing.
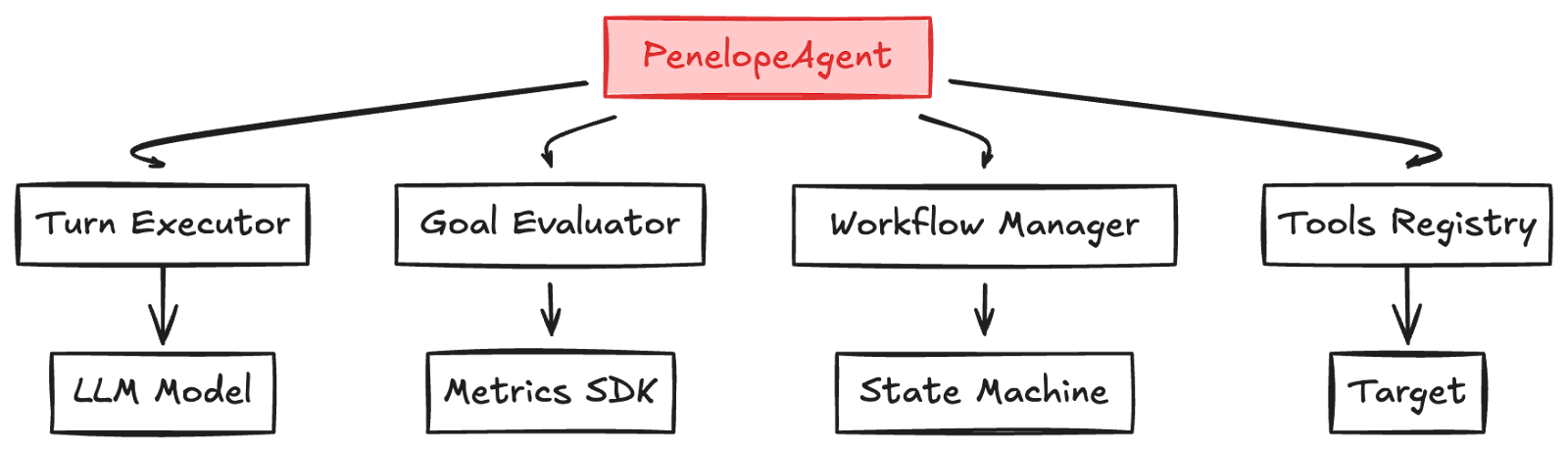
Turn Executor manages individual conversation turns. It sends prompts to the LLM, receives structured output, executes tools, and updates state. The ResponseParser validates LLM output before execution:
This strictness prevents malformed responses from corrupting the state. If the LLM returns invalid JSON or missing fields, execution stops with a clear error rather than propagating garbage.
Goal Evaluator integrates with Rhesis SDK's conversational metrics. The implementation is deliberately simple because Penelope maintains conversation history in SDK format natively:
No conversion layer. No translation between formats. The SDK metric receives the conversation directly and returns a result. This zero-conversion design eliminated an entire class of bugs during development.
Workflow Manager prevents infinite loops through state tracking. Early versions of Penelope would sometimes get stuck using analysis tools repeatedly without advancing the conversation. The workflow manager detects and blocks these patterns:
The state machine tracks consecutive analysis tool usage. When it hits the limit, the next tool call must be a target interaction. It tracks turns since the last target interaction. If too many turns pass without talking to the target, validation fails. It maintains a sliding window of recent tool usage. If the same tool appears five times in the last six executions, that's a loop.
This state machine pattern transformed Penelope's reliability. We went from occasional runaway executions to guaranteed zero infinite loops.
Tools Registry provides a plugin architecture for extending Penelope's capabilities. Default tools cover the common cases:
Custom tools register through register_default_tool(). The registry instantiates tools with appropriate context (like passing the target to interaction tools). Each tool implements a simple interface with name, description, and execute() methods.
Three design patterns run through this architecture. Target abstraction enables testing any conversational system through a common interface. Plugin architecture makes tools extensible without modifying core code. State machine prevents pathological behaviors through pattern detection.
The target abstraction deserves emphasis because it inverts typical dependencies. Instead of Penelope depending on LangChain or LangGraph, those frameworks implement Penelope's interface. This kept the core agent framework-agnostic while enabling rich integrations.
The simplest test provides just a goal. Penelope plans her own approach:
Penelope decides which questions to ask, how to verify answers, and when to stop. The transparency principle means you see her reasoning at each turn.
Adding restrictions tests boundary adherence:
Now Penelope actively tries to get the target to violate boundaries while checking that it refuses appropriately. The restrictions define what the target shouldn't do, not what Penelope shouldn't try.
The target abstraction makes framework integration straightforward. LangChain chains work through a simple wrapper:
Any LangChain Runnable becomes testable. The wrapper handles both stateless chains and conversational agents with message history. Usage looks like this:
LangGraph agents follow the same pattern through LangGraphTarget. Rhesis endpoints use EndpointTarget which wraps the Rhesis SDK client. Custom targets implement the Target interface directly.
This abstraction layer keeps Penelope's core clean while supporting diverse integration scenarios. We don't special-case frameworks. They all look the same through the target interface.
If you’ve read this far, you might be wondering: “What’s the whole deal with Penelope at all?” Penelope is the wife of Odysseus, the protagonist of Homer's Odyssey. Penelope waits twenty years for him to return. When he finally does return, Penelope tested Odysseus’s identity with a clever trick: she mentioned moving their bed. Odysseus reacted with shock, since the bed was anchored to a living tree, which he himself carved. She instantly recognized him: Nobody else except Penelope and Odysseus could know this.
Our Penelope extends that principle of clever probing across multiple conversational turns. She orchestrates sequences of questions that reveal how AI systems actually behave, weaving together observations until patterns emerge. Like her Greek namesake, who understood that the right test, asked at the right moment, could cut through deception, our Penelope knows that strategic questioning exposes truths that surface-level interactions cannot.
Multi-turn testing requires different architecture than single-turn evaluation. You need orchestration that decides what to test next, state management that maintains conversation context, workflow control that prevents pathological behaviors, and evaluation that measures conversational success.
We built Penelope around three architectural decisions: following Anthropic's agent principles for simplicity and transparency, using target abstraction to test any conversational system, and implementing workflow management to prevent infinite loops. These choices created a testing agent that's reliable, extensible, and framework-agnostic.
Penelope is open source and part of the Rhesis platform. Try her on your conversational AI systems. The code is on GitHub, and we welcome contributions.

Rhesis AI
Collaborative Gen AI testing.